Llamaindex Prompt Template
Llamaindex Prompt Template - How to add new documents to an existing index asked 8 months ago modified 7 months ago viewed 944 times I'm trying to use llamaindex with my postgresql database. Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst performing embedding models. Is there a way to adapt text nodes, stored in a collection in a wdrant vector store, into a format that's readable by langchain? I already have vector in my database. 0 i'm using azureopenai + postgresql + llamaindex + python. Now, i want to merge these two indexes into a. The akash chat api is supposed to be compatible with openai : Llamaindex is also more efficient than langchain, making it a better choice for applications that need to process large amounts of data. The goal is to use a langchain retriever that can. 0 i'm using azureopenai + postgresql + llamaindex + python. Now, i want to merge these two indexes into a. Is there a way to adapt text nodes, stored in a collection in a wdrant vector store, into a format that's readable by langchain? Llamaindex is also more efficient than langchain, making it a better choice for applications that need to process large amounts of data. I'm working on a python project involving embeddings and vector storage, and i'm trying to integrate llama_index for its vector storage capabilities with postgresql. I'm working with llamaindex and have created two separate vectorstoreindex instances, each from different documents. I'm trying to use llamaindex with my postgresql database. Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst performing embedding models. The goal is to use a langchain retriever that can. The akash chat api is supposed to be compatible with openai : I'm trying to use llamaindex with my postgresql database. Llamaindex is also more efficient than langchain, making it a better choice for applications that need to process large amounts of data. I already have vector in my database. Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst performing. I'm working with llamaindex and have created two separate vectorstoreindex instances, each from different documents. The akash chat api is supposed to be compatible with openai : I already have vector in my database. Is there a way to adapt text nodes, stored in a collection in a wdrant vector store, into a format that's readable by langchain? I'm working. I'm trying to use llamaindex with my postgresql database. Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst performing embedding models. I'm working on a python project involving embeddings and vector storage, and i'm trying to integrate llama_index for its vector storage capabilities with postgresql. I'm working with. I'm working on a python project involving embeddings and vector storage, and i'm trying to integrate llama_index for its vector storage capabilities with postgresql. The goal is to use a langchain retriever that can. Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst performing embedding models. I'm trying. How to add new documents to an existing index asked 8 months ago modified 7 months ago viewed 944 times Now, i want to merge these two indexes into a. I'm trying to use llamaindex with my postgresql database. Llamaindex is also more efficient than langchain, making it a better choice for applications that need to process large amounts of. The akash chat api is supposed to be compatible with openai : Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst performing embedding models. I'm trying to use llamaindex with my postgresql database. Now, i want to merge these two indexes into a. I already have vector in. The goal is to use a langchain retriever that can. Now, i want to merge these two indexes into a. I already have vector in my database. I'm working with llamaindex and have created two separate vectorstoreindex instances, each from different documents. I'm trying to use llamaindex with my postgresql database. I already have vector in my database. The akash chat api is supposed to be compatible with openai : I'm trying to use llamaindex with my postgresql database. Llamaindex is also more efficient than langchain, making it a better choice for applications that need to process large amounts of data. I'm working with llamaindex and have created two separate vectorstoreindex. I'm trying to use llamaindex with my postgresql database. The goal is to use a langchain retriever that can. I'm working on a python project involving embeddings and vector storage, and i'm trying to integrate llama_index for its vector storage capabilities with postgresql. I'm working with llamaindex and have created two separate vectorstoreindex instances, each from different documents. Now, i. I'm working with llamaindex and have created two separate vectorstoreindex instances, each from different documents. Is there a way to adapt text nodes, stored in a collection in a wdrant vector store, into a format that's readable by langchain? Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst. The goal is to use a langchain retriever that can. I'm working with llamaindex and have created two separate vectorstoreindex instances, each from different documents. Openai's gpt embedding models are used across all llamaindex examples, even though they seem to be the most expensive and worst performing embedding models. The akash chat api is supposed to be compatible with openai : I'm trying to use llamaindex with my postgresql database. Now, i want to merge these two indexes into a. 0 i'm using azureopenai + postgresql + llamaindex + python. How to add new documents to an existing index asked 8 months ago modified 7 months ago viewed 944 times I already have vector in my database.Createllama chatbot template for multidocument analysis LlamaIndex
How prompt engineering can boost RAG pipeline LlamaIndex posted on
at
LlamaIndex Prompt Engineering Tutorial (FlowGPT) PDF Data

Optimizing TexttoSQL Refining LlamaIndex Prompt Templates by Hamna
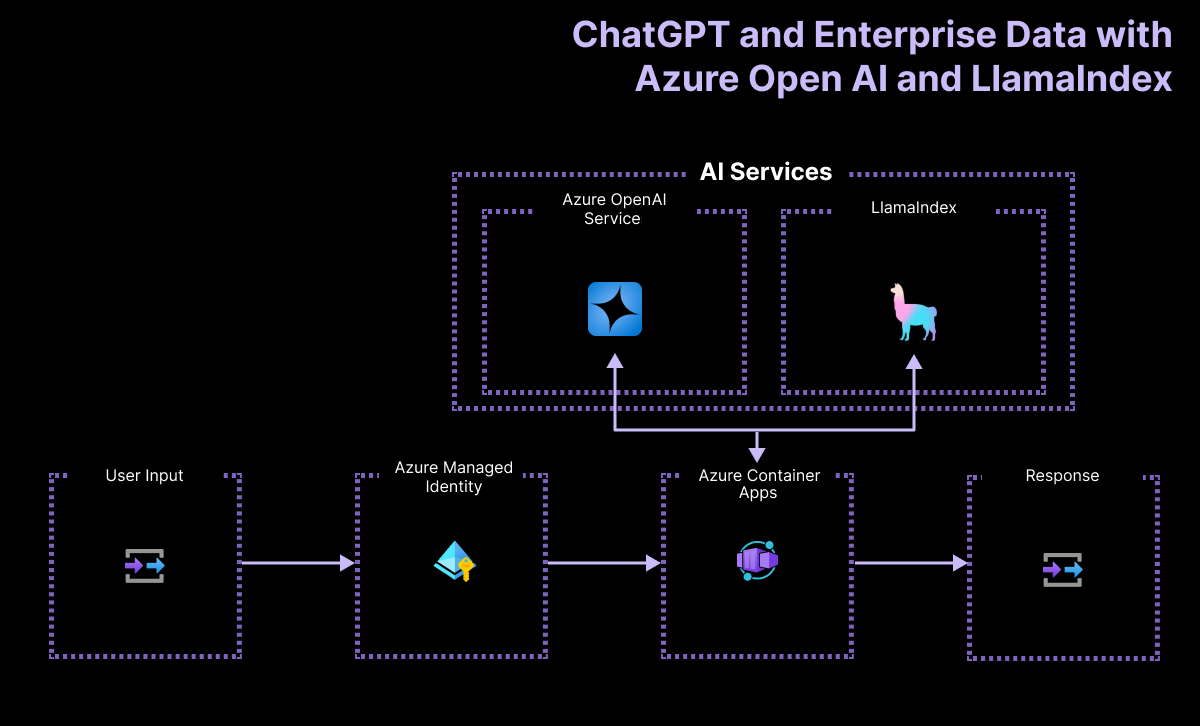
Get started with Serverless AI Chat using LlamaIndex JavaScript on

Prompt Engineering with LlamaIndex and OpenAI GPT3 by Sau Sheong
LlamaIndex on LinkedIn Advanced Prompt Engineering for RAG ️🔎 To

Optimizing TexttoSQL Refining LlamaIndex Prompt Templates by Hamna

LlamaIndex 02 Prompt Template in LlamaIndex Python LlamaIndex
Is There A Way To Adapt Text Nodes, Stored In A Collection In A Wdrant Vector Store, Into A Format That's Readable By Langchain?
I'm Working On A Python Project Involving Embeddings And Vector Storage, And I'm Trying To Integrate Llama_Index For Its Vector Storage Capabilities With Postgresql.
Llamaindex Is Also More Efficient Than Langchain, Making It A Better Choice For Applications That Need To Process Large Amounts Of Data.
Related Post:



